微調(diào)大模型的數(shù)據(jù)隱私可能泄露?
最近華科和清華的研究團(tuán)隊(duì)聯(lián)合提出了一種成員推理攻擊方法,能夠有效地利用大模型強(qiáng)大的生成能力,通過自校正機(jī)制來檢測(cè)給定文本是否屬于大模型的微調(diào)數(shù)據(jù)集。
NeurIPS24論文 《Membership inference attacks against fine-tuned large language models via self-prompt calibration》,提出了一種基于自校正概率波動(dòng)的成員推理攻擊算法SPV-MIA,首次在微調(diào)大模型場(chǎng)景下將攻擊準(zhǔn)確度提高至90%以上。

成員推理攻擊(Membership Inference Attack)是一種常見的針對(duì)機(jī)器學(xué)習(xí)模型的隱私攻擊方法。該攻擊可以判斷某個(gè)特定的輸入數(shù)據(jù)是否是模型訓(xùn)練數(shù)據(jù)集的一部分,從而導(dǎo)致訓(xùn)練數(shù)據(jù)集相關(guān)的隱私被泄露。例如,該攻擊通過判斷某個(gè)用戶的信息是否被用于模型訓(xùn)練來推斷該用戶是否使用了對(duì)應(yīng)的服務(wù)。此外,該攻擊還可用于鑒別非授權(quán)訓(xùn)練數(shù)據(jù),為機(jī)器學(xué)習(xí)模型訓(xùn)練集的版權(quán)鑒別提供了一個(gè)極具前景的解決方案。
盡管該攻擊在傳統(tǒng)機(jī)器學(xué)習(xí)領(lǐng)域,包括分類、分割、推薦等模型上已經(jīng)取得了大量的研究進(jìn)展并且發(fā)展迅速。然而針對(duì)大模型(Large Language Model,LLM)的成員推理攻擊方法尚未取得令人滿意的進(jìn)展。由于大模型的大尺度數(shù)據(jù)集,高度泛化性等特征,限制了成員推理攻擊的準(zhǔn)確性。
得益于大模型自身的強(qiáng)大的擬合和泛化能力,算法集成了一種自提示(Self-Prompt)方法,通過提示大模型自身生成在分布上近似訓(xùn)練集的校正數(shù)據(jù)集,從而獲得更好的成員推理分?jǐn)?shù)校正性能。此外,算法基于大模型的記憶性現(xiàn)象進(jìn)一步設(shè)計(jì)了一種概率波動(dòng)(Probabilistic Variation)成員推理攻擊分?jǐn)?shù),以保證攻擊算法在現(xiàn)實(shí)場(chǎng)景中穩(wěn)定的鑒別性能。基于上述兩種方法,該攻擊算法實(shí)現(xiàn)了微調(diào)大模型場(chǎng)景下精確的成員推理攻擊,促進(jìn)了未來針對(duì)大模型數(shù)據(jù)隱私及版權(quán)鑒別的相關(guān)研究。
現(xiàn)實(shí)場(chǎng)景中成員推理接近于隨機(jī)猜測(cè)
現(xiàn)有的針對(duì)語(yǔ)言模型的成員推理攻擊方法可以分為基于校正(Reference-based)和無(wú)校正(Reference-free)的兩種范式。其中無(wú)校正的成員推理攻擊假設(shè)訓(xùn)練集中的文本數(shù)據(jù)具有更高的生成概率(即在目標(biāo)語(yǔ)言模型上更低的Loss),因此無(wú)校正的攻擊范式可簡(jiǎn)單地通過判斷樣本生成概率是否高于預(yù)設(shè)閾值來鑒別訓(xùn)練集文本。

△Reference-free 無(wú)校正的成員推理攻擊流程圖
基于校正的成員推理攻擊認(rèn)為部分常用文本可能存在過度表征(Over-representative)的特征,即天然傾向于具有更高的概率被生成。因此該攻擊范式使用了一種困難度校正(Difficulty Calibration)的方法,假設(shè)訓(xùn)練集文本會(huì)在目標(biāo)模型上取得相較于校正模型更高的生成概率,通過比較目標(biāo)大模型和校正大模型之間的生成概率差異來篩選出生成概率相對(duì)較高的文本。

△Reference-based 基于校正的成員推理攻擊流程圖
然而,現(xiàn)有的兩種成員推理攻擊范式依賴于兩個(gè)在現(xiàn)實(shí)場(chǎng)景中無(wú)法成立的假設(shè):1)可以獲得與訓(xùn)練集具有相同數(shù)據(jù)分布的校正數(shù)據(jù)集,2)目標(biāo)大型語(yǔ)言模型存在過擬合現(xiàn)象。 如下圖 (a)所示,我們分別使用與目標(biāo)模型訓(xùn)練集同分布、同領(lǐng)域、不相關(guān)的三個(gè)不同的校正數(shù)據(jù)集用于微調(diào)校正模型。 無(wú)校正的攻擊性能始終較低,并且與數(shù)據(jù)集來源無(wú)關(guān)。對(duì)于基于校正的攻擊,隨著校正數(shù)據(jù)集與目標(biāo)數(shù)據(jù)集之間相似性的下降,攻擊性能呈現(xiàn)出災(zāi)難性地下降。如下圖(b)所示,現(xiàn)有的兩種攻擊范式都僅能在呈現(xiàn)出過擬合現(xiàn)象的大模型中取得良好的攻擊性能。因此,現(xiàn)有的范式在現(xiàn)實(shí)場(chǎng)景中只能取得接近于隨機(jī)猜測(cè)的鑒別性能。

△現(xiàn)有攻擊范式在現(xiàn)實(shí)場(chǎng)景中的鑒別性能接近于隨機(jī)猜測(cè)
為了解決上述的兩點(diǎn)挑戰(zhàn),我們提出了一種基于自校正概率波動(dòng)的成員推斷攻擊(Self-calibrated Probabilistic Variation based Membership Inference Attack,SPV-MIA),由兩個(gè)相應(yīng)模塊組成:1)大模型自校正機(jī)制:利用大模型本身生成高質(zhì)量校正數(shù)據(jù)集,2)概率波動(dòng)估計(jì)方法:提出概率波動(dòng)指標(biāo)刻畫大模型記憶現(xiàn)象特征,避免對(duì)模型過擬合的假設(shè)。
大模型自校正機(jī)制
在現(xiàn)實(shí)場(chǎng)景中,用于微調(diào)大模型的數(shù)據(jù)集通常具有極高的隱私性,因此從相同分布中采樣高質(zhì)量的校正數(shù)據(jù)集成為了一個(gè)看似不可能的挑戰(zhàn)。
我們注意到大模型具有革命性的擬合和泛化能力,使它們能夠?qū)W習(xí)訓(xùn)練集的數(shù)據(jù)分布,并生成大量富含創(chuàng)造力的文本。因此,大模型自身有潛力刻畫訓(xùn)練數(shù)據(jù)的分布。
因此,我們考慮一種自提示方法,通過用少量單詞提示目標(biāo)大模型自身,從目標(biāo)大模型本身收集校正數(shù)據(jù)集。
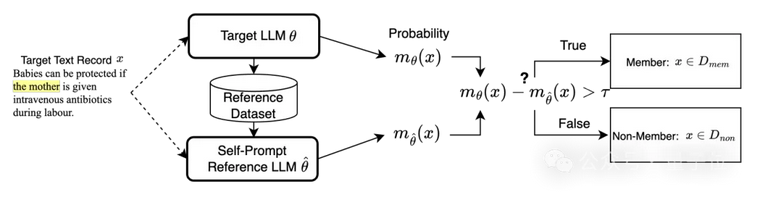
△大模型自校正機(jī)制方法流程圖
具體而言,我們首先從同一領(lǐng)域的公共數(shù)據(jù)集中收集一組長(zhǎng)度為l的文本塊,其中領(lǐng)域可從目標(biāo)大模型的任務(wù)中輕松推斷出來(例如,用于總結(jié)任務(wù)的大模型大概率在總結(jié)數(shù)據(jù)集上微調(diào))。然后,我們將長(zhǎng)度為l的每個(gè)文本塊用作提示文本,并請(qǐng)求目標(biāo)大模型生成文本。
所有生成的文本可以構(gòu)成一個(gè)大小為N的數(shù)據(jù)集,用于微調(diào)自提示校正模型 。因此,利用自提示校正模型校正的成員推理分?jǐn)?shù)可寫為: 其中校正數(shù)據(jù)集從目標(biāo)大模型中采樣得到: , and 分別是在目標(biāo)模型和校正模型上評(píng)估得到的成員推理分?jǐn)?shù)。
概率波動(dòng)估計(jì)方法
現(xiàn)有的攻擊范式隱式假設(shè)了訓(xùn)練集文本被生成的概率比非訓(xùn)練集文本更高,而這一假設(shè)僅在過擬合模型中得到滿足。
然而現(xiàn)實(shí)場(chǎng)景中的微調(diào)大模型通常僅存在一定程度的記憶現(xiàn)象。盡管記憶與過擬合有關(guān),但過擬合本身并不能完全解釋記憶的一些特性。記憶和過擬合之間的關(guān)鍵差異可以總結(jié)為以下三點(diǎn):
發(fā)生時(shí)間:過擬合在驗(yàn)證集困惑度(PPL)首次上升時(shí)開始,而記憶更早發(fā)生并貫穿訓(xùn)練全程。
危害程度:過擬合通常,而記憶對(duì)某些任務(wù)(如QA)可能至關(guān)重要。
避免難度:記憶不可避免,即使早停止(Early-stopping)也無(wú)法消除,且減輕非預(yù)期記憶(如逐字記憶)極為困難。
因此,記憶現(xiàn)象更適合作為鑒別訓(xùn)練集文本的信號(hào)。生成模型中的記憶會(huì)導(dǎo)致成員記錄比數(shù)據(jù)分布中的鄰近記錄具有更高的生成概率。

△過擬合與記憶現(xiàn)象在模型概率分布上的差異
這一原則可以與大模型共享,因?yàn)樗鼈兛梢员灰暈槲谋旧赡P汀?/p>
因此,我們?cè)O(shè)計(jì)了一個(gè)更有前景的成員推理分?jǐn)?shù),通過確定該文本是否位于目標(biāo)模型 概率分布上的局部最大值點(diǎn): 其中 是由改寫模型采樣得到的一組對(duì)稱的文本對(duì),這種改寫可被視為在文本高維表征空間上的微小擾動(dòng)。本文中使用了Mask Filling Language Model (T5-base)分別在語(yǔ)義空間和表征空間上對(duì)目標(biāo)文本進(jìn)行擾動(dòng)。
實(shí)驗(yàn)結(jié)果:僅需1.000次查詢,達(dá)到超過90%的準(zhǔn)確度
為了評(píng)估攻擊算法SPV-MIA的有效性,本研究在四個(gè)開源的大模型GPT-2.GPT-J,F(xiàn)alcon-7B,LLaMA-7B和三個(gè)不同領(lǐng)域的微調(diào)數(shù)據(jù)集Wikitext-103. AG News, XSum上進(jìn)行實(shí)驗(yàn)評(píng)估。
該研究采用了七種先進(jìn)的基線算法作為對(duì)比:
無(wú)校正的攻擊方法(Loss Attack、Neighbour Attack、DetectGPT、Min-K%、Min-K%++)
基于校正的攻擊方法 (LiRA-Base、LiRA-Candidate)
對(duì)比實(shí)驗(yàn)驗(yàn)證了在上述大模型和微調(diào)數(shù)據(jù)集下所提方法相對(duì)于最先進(jìn)基線方法的顯著性能提升,從AUC分?jǐn)?shù)上看,提升幅度達(dá)30%。

△使用AUC分?jǐn)?shù)的性能對(duì)比(加粗處為最佳性能,下劃線處為次佳性能)
從1%假陽(yáng)率下的真陽(yáng)率(TPR@1% FPR)來看,提升幅度高達(dá)260%,表明SPV-MIA可以在極低的誤報(bào)率情況下取得極高的召回率。
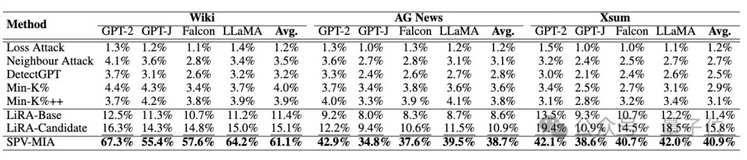
△使用1%假陽(yáng)率下的真陽(yáng)率的性能對(duì)比(加粗處為最佳性能,下劃線處為次佳性能)
此外,本文探究了基于校正的成員推理攻擊方法如何依賴于校正數(shù)據(jù)集的質(zhì)量,并評(píng)估我們提出的方法是否能構(gòu)建出高質(zhì)量的校正數(shù)據(jù)集。本實(shí)驗(yàn)評(píng)估了在同分布、同領(lǐng)域、不相關(guān)數(shù)據(jù)集和通過自提示機(jī)制構(gòu)建的數(shù)據(jù)集上,基于校正的成員推理攻擊性能。實(shí)驗(yàn)結(jié)果表明提出的自提示機(jī)制可以構(gòu)建出近似于同分布的高質(zhì)量數(shù)據(jù)集。

△使用不同校正數(shù)據(jù)集時(shí)成員推理攻擊的性能
在現(xiàn)實(shí)世界中,攻擊者可用的自提示文本來源通常受到實(shí)際部署環(huán)境的限制,有時(shí)甚至無(wú)法獲取特定領(lǐng)域的文本。并且自提示文本的規(guī)模通常受限于 大模型 API 的訪問頻率上限和可用自提示文本的數(shù)量。為了進(jìn)一步探究SPV-MIA在復(fù)雜的實(shí)際場(chǎng)景下的魯棒性,本文從自提示文本來源,尺度,長(zhǎng)度三個(gè)角度探究在極端情況下的成員推理攻擊性能。
實(shí)驗(yàn)結(jié)果表明對(duì)于不同來源的提示文本,自提示方法對(duì)提示文本來源的依賴性低得令人難以置信。即使使用完全不相關(guān)的提示文本,攻擊性能也只會(huì)出現(xiàn)輕微下降(最多 3.6%)。因此自提示方法在不同先驗(yàn)信息的攻擊者面前具有很強(qiáng)的通用性。

△SPV-MIA在不同來源自提示文本下的攻擊性能
并且自提示方法受查詢頻率的影響極低,只需要1.000次查詢即可達(dá)到接近于0.9的AUC分?jǐn)?shù)。此外,當(dāng)僅有8個(gè)tokens的自提示文本也可引導(dǎo)大模型生成高質(zhì)量的校正模型。
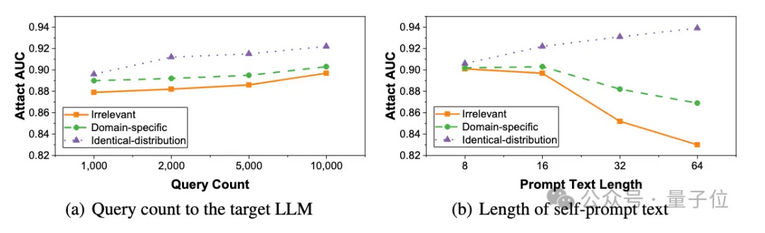
△SPV-MIA在不同尺度、長(zhǎng)度自提示文本下的攻擊性能
結(jié)論:
本文首先從兩個(gè)角度揭示了現(xiàn)有的成員推理攻擊在現(xiàn)實(shí)場(chǎng)景中無(wú)法對(duì)微調(diào)大模型造成有效的隱私泄露風(fēng)險(xiǎn)。為了解決這些問題,我們提出了一種基于自校正概率波動(dòng)的成員推理攻擊(SPV-MIA),其中我們提出了一種自提示方法,實(shí)現(xiàn)了在實(shí)際場(chǎng)景中從大型語(yǔ)言模型中提取校正數(shù)據(jù)集,然后引入了一種基于記憶而非過擬合的更可靠的成員推理分?jǐn)?shù)。我們進(jìn)行了大量實(shí)驗(yàn)證明了SPV-MIA相對(duì)于所有基線的優(yōu)越性,并驗(yàn)證了其在極端條件下的有效性。
論文鏈接:https://openreview.net/forum?id=PAWQvrForJ。
代碼鏈接:https://github.com/tsinghua-fib-lab/NeurIPS2024_SPV-MIA。


