

抖音集團(tuán)安全研究團(tuán)隊(duì)和南方科技大學(xué)可信系統(tǒng)安全實(shí)驗(yàn)室合作的研究論文揭示了大語言模型安全領(lǐng)域服務(wù)框架的側(cè)信道漏洞,利用多租戶場(chǎng)景下的KV緩存共享機(jī)制精確恢復(fù)了用戶提示詞。本工作成果《I Know What You Asked: Prompt Leakage via KV-Cache Sharing in Multi-Tenant LLM Serving》已被安全領(lǐng)域頂級(jí)會(huì)議NDSS 2025接收。
一、研究背景
大語言模型(LLM)在自然語言處理任務(wù)中取得了顯著進(jìn)展,廣泛應(yīng)用于文本生成、翻譯、問答等領(lǐng)域,吸引了學(xué)術(shù)界和工業(yè)界的高度關(guān)注。這些模型在提供高效、準(zhǔn)確的語言處理服務(wù)的同時(shí),也面臨著由于計(jì)算資源需求巨大所帶來的性能瓶頸。為了滿足不同用戶的使用需求,優(yōu)化資源利用率,大量多租戶LLM框架應(yīng)運(yùn)而生,通過共享資源和更高效的調(diào)度算法,實(shí)現(xiàn)性能和成本的有效優(yōu)化。
在眾多多租戶LLM的框架中,一個(gè)廣泛應(yīng)用的技術(shù)就是KV緩存共享(包括SGLang、vLLM等)。KV緩存共享的基本原理是允許不同請(qǐng)求在推理過程中復(fù)用已經(jīng)計(jì)算過的KV緩存,但這種共享僅在前序token序列完全相同時(shí)才能實(shí)現(xiàn)。這種設(shè)計(jì)保證了不同用戶的請(qǐng)求在一定程度上可以復(fù)用計(jì)算結(jié)果,提升了推理效率。目前SGLang提供了SOTA的KV緩存共享策略。具體而言,SGLang使用了一種基于Radix樹的結(jié)構(gòu)以便快速索引和訪問。此外,SGLang實(shí)現(xiàn)了一種優(yōu)化的調(diào)度算法,確保優(yōu)先處理?yè)碛懈L(zhǎng)復(fù)用匹配的請(qǐng)求,以最大化緩存命中率并減少重復(fù)計(jì)算。

在我們最新發(fā)表于NDSS 2025的論文《I Know What You Asked: Prompt Leakage via KV-Cache Sharing in Multi-Tenant LLM Serving》中,我們首次利用不同用戶間共享KV緩存的特性,實(shí)現(xiàn)了跨用戶的提示竊取。這一研究揭示了當(dāng)前多租戶LLM服務(wù)框架在共享資源使用中的巨大潛在安全風(fēng)險(xiǎn)。抖音集團(tuán)安全研究團(tuán)隊(duì)已經(jīng)與SGLang建立聯(lián)系,反映了上述安全問題。相關(guān)安全補(bǔ)丁將于近日提交至開源倉(cāng)庫(kù)。

二、攻擊方法
攻擊核心:如果攻擊者能夠觀察到自身請(qǐng)求是否觸發(fā)了KV緩存共享,則可以判斷其請(qǐng)求與已處理的請(qǐng)求是否相同或部分相同。攻擊者通過每次增加一個(gè)token并反復(fù)請(qǐng)求,從而逐個(gè)token地還原出其他用戶的請(qǐng)求內(nèi)容。
接下來,我們用攻擊過程中的一個(gè)片段來闡述攻擊者如何還原其他用戶請(qǐng)求中的一個(gè)token。通過反復(fù)重復(fù)這一操作,攻擊者最終可以還原出完整請(qǐng)求。
如下圖所示,假設(shè)目標(biāo)語句是“Imagine you are an IT expert”,攻擊者已經(jīng)成功還原出“Imagine you are”,并企圖還原出下一個(gè)token “an”。
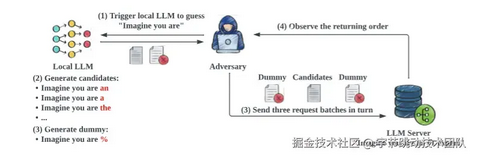
本地候選生成:攻擊者利用本地LLM來生成可能的token。本地LLM不需要和目標(biāo)LLM完全相同,只要擁有相同的Tokenizer來確保能夠匹配到目標(biāo)LLM的解析方法即可。在這個(gè)例子中,本地LLM可能會(huì)生成“a”,“an”,“the”等潛在的候選token。同時(shí),本地LLM也會(huì)生成一個(gè)最不可能的token作為dummy token,為之后的攻擊使用。
候選請(qǐng)求發(fā)送:在生成本地候選之后, 攻擊者會(huì)將三批請(qǐng)求依次發(fā)送,分別為由dummy token構(gòu)成的dummy batch,候選token構(gòu)成的候選batch,和另一批由dummy token構(gòu)成的dummy batch。這樣的設(shè)定是為了更容易觀測(cè)到的側(cè)信道信息。
側(cè)信道結(jié)果觀測(cè):通過觀測(cè)發(fā)送請(qǐng)求的返回順序作為側(cè)信道信息,攻擊者可以判斷哪個(gè)請(qǐng)求成功觸發(fā)KV緩存共享,從而確定對(duì)應(yīng)的token。接下來我們對(duì)側(cè)信道信息進(jìn)行具體介紹。
側(cè)信道信息:我們利用調(diào)度算法的特性,即與已有KV緩存匹配更長(zhǎng)的請(qǐng)求會(huì)被優(yōu)先處理,來實(shí)現(xiàn)攻擊。成功匹配的請(qǐng)求相比未匹配的請(qǐng)求多一個(gè)token匹配,因此更早被處理。我們將請(qǐng)求的返回順序作為側(cè)信道信息,通過觀察哪個(gè)請(qǐng)求被優(yōu)先返回,從而判斷其是否觸發(fā)了緩存共享。
如下圖所示,當(dāng)我們按照三個(gè)批次發(fā)送請(qǐng)求后,是否有匹配到的請(qǐng)求會(huì)有不同的處理模式:
沒有觸發(fā)KV緩存共享:對(duì)于沒有觸發(fā)的場(chǎng)景,dummy請(qǐng)求的匹配長(zhǎng)度為4(在第一個(gè)dummy請(qǐng)求被處理后后續(xù)請(qǐng)求都會(huì)有更長(zhǎng)的匹配長(zhǎng)度),而candidates請(qǐng)求的匹配長(zhǎng)度為3.所以具體處理順序依次為:第一個(gè)dummy batch,第二個(gè)dummy batch,和candidates batch。
觸發(fā)KV緩存共享:對(duì)于成功觸發(fā)KV緩存共享的場(chǎng)景,dummy請(qǐng)求的匹配長(zhǎng)度依舊為4.此時(shí)成功匹配的匹配長(zhǎng)度也為4.其他的未匹配的請(qǐng)求的匹配長(zhǎng)度為3.所以此時(shí)的具體處理順序?yàn)椋旱谝粋€(gè)dummy batch,匹配到的請(qǐng)求,第二個(gè)dummy batch,和其余的candidates。這里第二個(gè)dummy batch可以幫助放大順序改變帶來的差異,從而能夠令攻擊者在端側(cè)判斷出順序的改變。

通過反復(fù)重復(fù)這一操作,攻擊者最終可以還原出完整請(qǐng)求。
三、實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)環(huán)境:實(shí)驗(yàn)環(huán)境基于SGLang框架,用戶請(qǐng)求設(shè)定參考了OpenAI的標(biāo)準(zhǔn),每3小時(shí)發(fā)送40次請(qǐng)求,以模擬真實(shí)的LLM使用場(chǎng)景。提示數(shù)據(jù)集包含四類:常規(guī)聊天、填空、角色扮演和指令型提示,用于全面評(píng)估攻擊效果和成本。
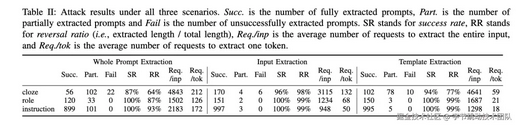
下圖展示了攻擊的最終效果。結(jié)果表明,在Llama2-13B模型上,攻擊者在知曉提示模版來回復(fù)提示輸入上成功率達(dá)99%,知曉提示輸入恢復(fù)提示模板成功率為98%,甚至在無任何背景知識(shí)恢復(fù)全部請(qǐng)求也有95%的成功率。
四、總結(jié)與展望
無狀態(tài)與有狀態(tài)設(shè)計(jì):本工作基于有狀態(tài)的大語言模型服務(wù)框架,即對(duì)于用戶的共享KV緩存,開展輸入竊取攻擊,而這種攻擊的本質(zhì)是針對(duì)于系統(tǒng)的狀態(tài)延續(xù)所進(jìn)行的。在大型系統(tǒng)中,用戶數(shù)據(jù)的狀態(tài)延續(xù)往往伴隨著潛在的安全風(fēng)險(xiǎn),所以為了確保安全要盡可能做到單次服務(wù)后清除用戶狀態(tài),如蘋果近期提出的Private Computing Cloud。然而,對(duì)于延遲要求較高的服務(wù)場(chǎng)景,復(fù)用緩存等有狀態(tài)的設(shè)計(jì)難以避免,但面臨著諸如本篇工作的安全挑戰(zhàn)。在此基礎(chǔ)上,我們已基于本篇工作提出了更安全的KV緩存共享框架,為大語言模型服務(wù)提供安全性保障的同時(shí)實(shí)現(xiàn)了效率的提升。
多租戶LLM框架下的資源共享:現(xiàn)有的LLM服務(wù)框架會(huì)有很多允許多用戶/多請(qǐng)求間的共享資源(如KV,memory,Lora adapter),這些共享資源可以很大程度的提高服務(wù)性能,但是存在巨大的安全隱患(隱私泄漏,投毒等),所以在設(shè)計(jì)框架和部署服務(wù)的過程中需要謹(jǐn)慎處理基于共享資源的優(yōu)化。框架設(shè)計(jì)師和服務(wù)提供商需要在保持性能的同時(shí)引入足夠的隔離機(jī)制來保證多租戶間的安全性。
KV緩存的安全性考量:KV緩存作為L(zhǎng)LM中的獨(dú)特機(jī)制,雖然提升了推理效率,也為L(zhǎng)LM的安全性帶來了新的攻擊面。KV緩存與用戶的輸入token存在唯一對(duì)應(yīng)關(guān)系,這使得一旦出現(xiàn)KV緩存信息泄漏,攻擊者便能夠通過緩存內(nèi)容直接推測(cè)和重構(gòu)相應(yīng)的用戶請(qǐng)求,從而導(dǎo)致敏感信息的暴露。本篇工作是第一次注意到了KV緩存所帶來的安全風(fēng)險(xiǎn),希望能夠引起廣泛的針對(duì)這一新屬性的安全思考。
建立安全的LLM推理服務(wù):不知攻,焉知防?攻擊的意義是為系統(tǒng)防御設(shè)計(jì)指明方向——我們對(duì)SGLang提交的安全策略可以大大提高攻擊者的消耗,盡可能減少攻擊面。然而,從LLM服務(wù)的全局視角出發(fā),當(dāng)前的LLM推理服務(wù)框架安全能力尚不完善,需要多種安全機(jī)制保駕護(hù)航。因此,安全研究團(tuán)隊(duì)正在基于機(jī)密計(jì)算及密碼學(xué)技術(shù),在兼容多種推理框架的前提下,提供大模型可信推理服務(wù),歡迎大家交流參考。


