
一、傳統TCP/IP網絡傳輸困境
1.1 傳統以太網端到端傳輸系統開銷過大
在描述通信過程時的軟硬件關系時,我們通常將模型劃分為用戶層Userspace、內核Kernel以及硬件Hardware。
Userspace和Kernel實際上使用的是同一塊物理內存,但是出于安全考慮,Linux將內存劃分為用戶空間和內核空間。用戶層沒有權限訪問和修改內核空間的內存內容,只能通過系統調用陷入內核態,Linux的內存管理機制比較復雜。
一次典型的基于傳統以太網的通信過程的可以如下圖所示進行分層:

這個模型的數據流向大致是像上圖這個樣子,數據首先需要從用戶空間復制一份到內核空間,這一次復制由CPU完成,將數據塊從用戶空間復制到內核空間的Socket Buffer中。內核中軟件TCP/IP協議棧給數據添加各層頭部和校驗信息。最后網卡會通過DMA從內存中復制數據,并通過物理鏈路發送給對端的網卡。
而對端是完全相反的過程:硬件將數據包DMA拷貝到內存中,然后CPU會對數據包進行逐層解析和校驗,最后將數據復制到用戶空間。上述過程中的關鍵點是需要CPU全程參與整個數據的處理過程,即從用戶空間拷貝數據到內核空間、以及對數據進行組裝和解析等,數據量大的情況下,這將對CPU將造成很大的負擔。
傳統網絡中,“節點A給節點B發消息”實際上做的是“把節點A內存中的一段數據,通過網絡鏈路搬移到節點B的內存中”,而這一過程無論是發端還是收段,都需要CPU的指揮和控制,包括網卡的控制,中斷的處理,報文的封裝和解析等等。
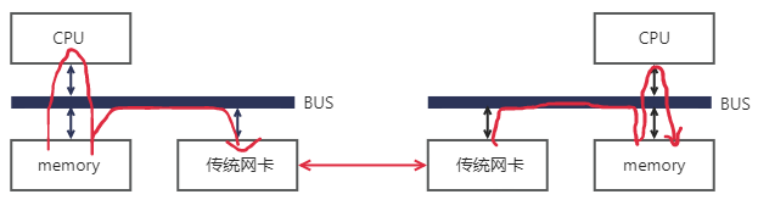
上圖中左邊的節點在內存用戶空間中的數據,需要經過CPU拷貝到內核空間的緩沖區中,然后才可以被網卡訪問,這期間數據會經過軟件實現的TCP/IP協議棧,加上各層頭部和校驗碼,比如TCP頭,IP頭等。網卡通過DMA拷貝內核中的數據到網卡內部的緩沖區中,進行處理后通過物理鏈路發送給對端。
對端收到數據后,會進行相反的過程:從網卡內部存儲空間,將數據通過DMA拷貝到內存內核空間的緩沖區中,然后CPU會通過TCP/IP協議棧對其進行解析,將數據取出來拷貝到用戶空間中。可以看到,即使有了DMA技術,上述過程還是對CPU有較強的依賴。
1.2 TCP協議本身在長肥管道場景下存在天然不足
- TCP長肥管道的兩大特征
①傳輸時延(發送時延)很小:收發包速度很快,非常短的時間就能把大量的數據發送到網絡上。
②傳播時延很大:數據包從發送到網絡上開始,要經過很長的時間(相比于發送時延)才能傳送到接收端。
- LFN對TCP性能的影響
①LFN的帶寬延時積很大(發送很快,傳播到另外一端需要很長時間),導致會有大量的數據包滯留在傳播途中TCP流控算法會在窗口變成0時停止發送。但原始的TCP頭部的窗口大小字段是16位的,因此窗口大小最大為65535字節,這就將發送方發送但未被確認的數據的總長度限制到了65536字節。參考計算65535*8/1024/1024=0.5Mbps,那么假設發送速度足夠快的前提下,在傳播時延為100毫秒的網絡里,只要5Mbps的帶寬就可以做到在第一個bit還沒有到達接收端時,發送端就已經發送完了最后一個bit, 然后窗口變成0,停止發送數據,還要等待至少100毫秒發送端才能收到接收端發回來的接收窗口通告,然后才能打開窗口繼續發送,意味著最多只能使用到5Mbps的帶寬,因此不能充分利用網絡。------由此提出了窗口擴大選項以聲明更大的窗口。
②LFN的高延時會導致管道枯竭
據TCP的擁塞控制,丟失分組會導致連接進行擁塞控制,即便是由于冗余ACK而進入了快速恢復,也會使得擁塞窗口降低一半,而如果是由于超時進入了慢啟動,則擁塞窗口會變為1,無論是哪一種情形,發送方允許被發送的數據量都大量減小了,這會使得管道枯竭,網絡通信速度急劇下降。
③LFN不利于TCP協議的RTT測量
按TCP協議,每個TCP連接只有一個RTT計時器, 同一時間,只有一個報文做RTT測量,啟動RTT計時的數據在沒有被ACK前, TCP無法進行下一次RTT的測量。而在長肥管道中,傳播時延很大,這意味著RTT的測試周期很大。
④LFN導致收端tcp亂序
長肥管的發送速度非常快(發送時延),TCP對每個字節數據使用一個32bit無符號的序號來進行標識。TCP定義了最大的報文段生存時間(MSL)來限制報文段在網絡中的生存時間。但是在LFN網絡上,由于序號空間是有限的,在已經傳輸了4294967296個字節以后序號會被重用。如果網絡快到在不到一個MSL的時候序號就發生了回繞,網絡中就會有兩個具有相同序號的不同的報文段,接收方將無法區分它們的順序。在一個千兆比特網絡(1000Mb/s)中只需要34秒就可以完成4294967296個字節的發送。
二、XDP的整體框架
2.1 基本原理
RDMA(Remote Direct Memory Access)意為遠程直接地址訪問,通過RDMA,本端節點可以“直接”訪問遠端節點的內存。所謂“直接”,指的是可以像訪問本地內存一樣,繞過傳統以太網復雜的TCP/IP網絡協議棧讀寫遠端內存,而這個過程對端是不感知的,而且這個讀寫過程的大部分工作是由硬件而不是軟件完成的。而使用了RDMA技術之后,這一過程可以簡單的表示成下面的示意圖:
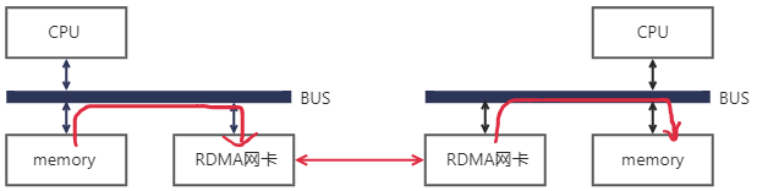
同樣是把本端內存中的一段數據,復制到對端內存中,在使用了RDMA技術時,兩端的CPU幾乎不用參與數據傳輸過程(只參與控制面)。本端的網卡直接從內存的用戶空間DMA拷貝數據到內部存儲空間,然后硬件進行各層報文的組裝后,通過物理鏈路發送到對端網卡。對端的RDMA網卡收到數據后,剝離各層報文頭和校驗碼,通過DMA將數據直接拷貝到用戶空間內存中。RDMA將服務器應用數據直接由內存傳輸到智能網卡(固化RDMA協議),由智能網卡硬件完成RDMA傳輸報文封裝,解放了操作系統和CPU。
2.2 核心優勢
1)Zero Copy(零拷貝):無需將數據拷貝到操作系統內核態并處理數據包頭部的過程,傳輸延遲會顯著減小。

2)Kernel Bypass(內核旁路) :不需要操作系統內核參與,數據通路中沒有繁瑣的處理報頭邏輯,不僅會使延遲降低,而且也大大節省了CPU的資源。
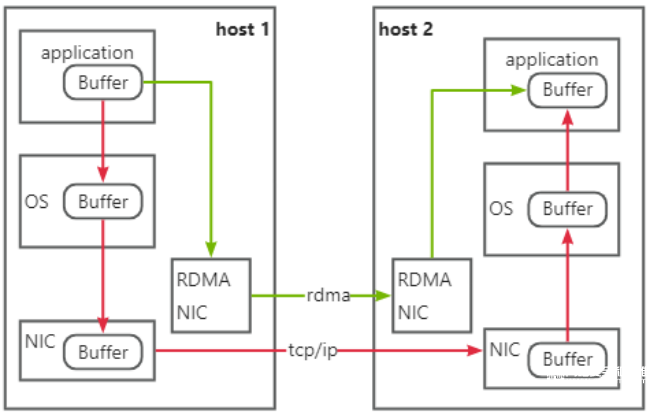
3)Protocol Offload(協議卸載):RDMA通信可以在遠端節點CPU不參與通信的情況下,對內存進行讀寫,這實際上是把報文封裝和解析放到硬件中做了。對比傳統的以太網通信,雙方CPU都必須參與各層報文的解析,如果數據量大且交互頻繁,對CPU來講將是一筆不小的開銷,而這些被占用的CPU計算資源本可以做一些更有價值的工作。
相比于傳統以太網,RDMA技術同時做到了更高帶寬和更低時延,所以其在帶寬敏感的場景——比如海量數據的交互,時延敏感——比如多個計算節點間的數據同步的場景下得以發揮其作用。
2.3 RDMA網絡基本分類
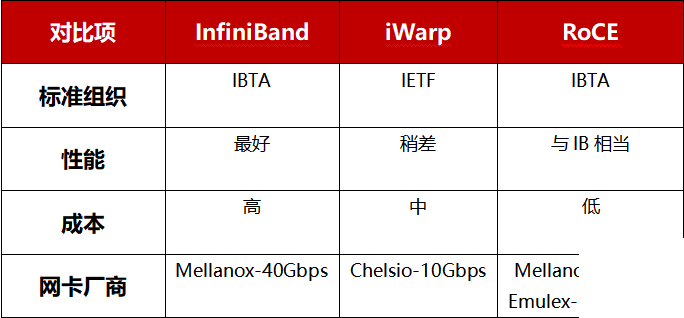
目前,大致有三類RDMA網絡,分別是InfiniBand、RoCE(RDMA over Converged Ethernet,RDMA過融合以太網)和iWARP(RDMA over TCP,互聯網廣域RDMA協議)。RDMA最早專屬于Infiniband網絡架構,從硬件級別保證可靠傳輸,而RoCE和iWARP都是基于以太網的RDMA技術。
1)InfiniBand
InfiniBand是一種專為RDMA設計的網絡, 由IBTA(InfiniBand Trade Association)在2000年提出,其規定了一整套完整的鏈路層到傳輸層(非傳統OSI七層模型的傳輸層,而是位于其之上)規范,主要采用Cut-Through轉發模式(直通轉發模式)以減少轉發時延,基于Credit的流控機制(基于信用的流控機制)以保證無丟包。但IB也存在不可避免的成本缺陷。由于其無法兼容現有以太網,除了需要支持IB的網卡之外,企業如果想部署的話還要重新購買配套的交換設備。
2)RoCE
RoCE有兩個版本:RoCEv1基于以太網鏈路層實現,v1版本網絡層仍然使用了IB規范,而v2使用了UDP+IP作為網絡層,使得數據包也可以被路由,只能在L2層傳輸;RoCEv2基于UDP承載RDMA,可部署于三層網絡。
RoCE可以被認為是IB的“低成本解決方案”,部署RoCE網絡需要支持RDMA專用智能網卡,不需要專用交換機和路由器(支持ECN/PFC等技術,降低丟包率),其建網成本在三種rdma網絡模型中最低。
3)iWARP
傳輸層為iWARP協議,iWARP是以太網TCP / IP協議中TCP層實現,支持L2 / L3層傳輸,大型組網TCP連接會消耗大量CPU,所以應用很少。
iWARP只要求網卡支持RDMA,不需要專用交換機和路由器,建網成本介于InfiniBand和RoCE之間。
2.4 實現對比
Infiniband技術先進,但是價格高昂,應用局限在HPC高性能計算領域,隨著RoCE和iWARPC的出現,RDMA的使用成本進一步,從而推動了RDMA技術普及。
在高性能存儲、計算數據中心中采用這三類RDMA網絡,都可以大幅度降低數據傳輸時延,并為應用程序提供更高的CPU資源可用性。
其中InfiniBand網絡為數據中心帶來極致的性能,傳輸時延低至百納秒,比以太網設備延時要低一個量級;
RoCE和iWARP網絡為數據中心帶來超高性價比,基于以太網承載RDMA,充分利用了RDMA的高性能和低CPU使用率等優勢,同時網絡建設成本也不高;
基于UDP協議的RoCE比基于TCP協議的iWARP性能更好,結合無損以太網的流控技術,解決了丟包敏感的問題,RoCE網絡已廣泛應用于各行業高性能數據中心中。
三、RDMA在家寬網絡中的應用探索
在“網絡強國、數字中國、智慧社會”等國家戰略的全面推進下,數字化、網絡化、智能化的數字家庭已經成為智慧城市理念在家庭層面的體現,“十四五”規劃和2035遠景目標中,數字家庭被定位為構筑“美好數字生活新圖景”的重要組成部分,在新一代信息技術的支持下,數字家庭正向智慧家庭不斷演進,完成從“數字”到“智慧”的轉變。當前,中國智慧家庭市場規模逐年擴大,中國已成為全球最大的智能家居市場消費國,占據全球約50%~60%的市場份額(數據來源:CSHIA,艾梅數據,國家統計局)。據賽迪顧問研究預計,2030年中國智慧家庭市場規模將會達到15700億元,2021—2030年平均復合增長率(CAGR)高達14.6%。
伴隨著家寬市場規模的快速發展是:
① 家寬無差異化、盡力而為的服務方式與業務差異化、確定性網絡質量需求間的矛盾
當前寬帶接入對不同業務網絡連接不做差異化區別,以盡力而為方式提供服務,在擁塞時所有業務優先級相同,采用的處理策略相同。但業務對網絡質量要求不同,對時延丟包等敏感度不同,部分時延敏感業務如游戲、云電腦等需要確定性網絡保障,為確保用戶體驗,在網絡擁塞丟包時,用戶體驗急劇下降,因此在擁塞時對此類業務需要不同的處理策略。
② 帶寬提升與長肥管道場景體驗劣化間的矛盾
根據工信部統計數據,全國100Mbps以上寬帶用戶占比超過94%,但用戶在訪問遠距離內容時仍存在卡頓、下載速度慢的問題。其原因不是接入帶寬不足,而是底層TCP協議擁塞控制算法在長肥管道(LFN)場景下的天然不足。TCP為幾十年前的協議,已無法適應目前的網絡狀態與應用需求,亟需新的協議與算法來確保長肥管道場景下的業務體驗。
綜上,從行業趨勢上來看,在家寬網絡算力化升級的浪潮之下,RDMA技術相比于TCP而言,能夠實現計算和網絡的深度融合。將數據直接從一臺計算機的內存傳輸到另一臺計算機,無需雙方操作系統的介入,不需要經過處理器耗時的處理,最終達到高帶寬、低時延和低資源占用率的效果。


