軟件項目最初沒有的運維部門
大概12年前,最初進入軟件開發領域,那時一個人需要學很多的開發技能和運維技能,上能后端做服務,下能前端寫頁面,左能做DBA,右能做架構,中間還能運維。
那時開發和運維其實沒有界限,基本都是一體的,當然也有可能因為公司規模不是特別大,所以分工也沒有那么細,也聽說過專門有運維部門的公司,但是那時軟件運維人員的水平也只能做重復性的工作。
硬件和網絡運維這里不講,而那種比較貴的DBA,中小公司一般不會請,所以基本上開發≈運維。
軟件生命周期中最長的部分在運維階段,在那個時候開發是要負責整個生命周期的。
那個時候架構很簡單,有的應用程序、數據庫、文件都部署在一臺服務器上:
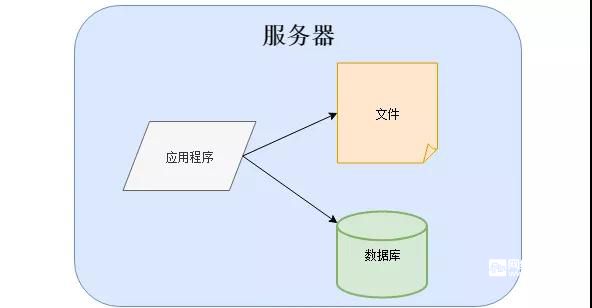
或者是分開部署,將應用程序、數據庫、文件各自部署在獨立的服務器上,并且根據服務器的用途配置不同的硬件,達到最佳的性能效果:
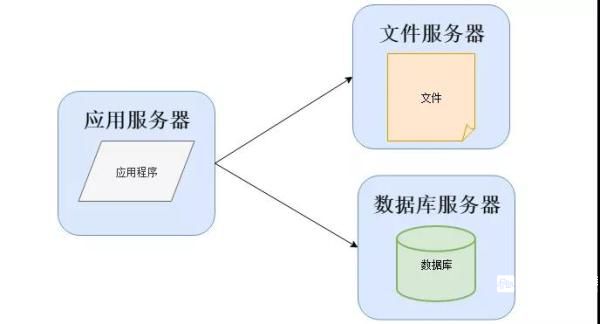
數據庫的選擇一般情況下有三個:大、中型系統使用Oracle或者MSSQL,畢竟會有廠商進行支持,DBA的質量也比較高。
小型系統一般使用MySQL,使用的好壞基本依賴開發人員對MySQL的熟悉程度。
然而到了今天,會有專業的人在做開源或者非開源數據庫的維護,數據庫市場也迎來了百花齊放的春天。
隨著業務擴展開始出現分工
當越來越多的人開始使用軟件系統,開發的工作日漸繁忙,多數時候在忙著寫代碼和做項目,運維的工作很多時候無法抽身。
這個時候會將幾個之前開發系統的程序員組成一個新的組織,這個就是軟件運維部門的雛形,他們為了解決一些性能上的問題,可能改變系統架構與部署,比如加入緩存:
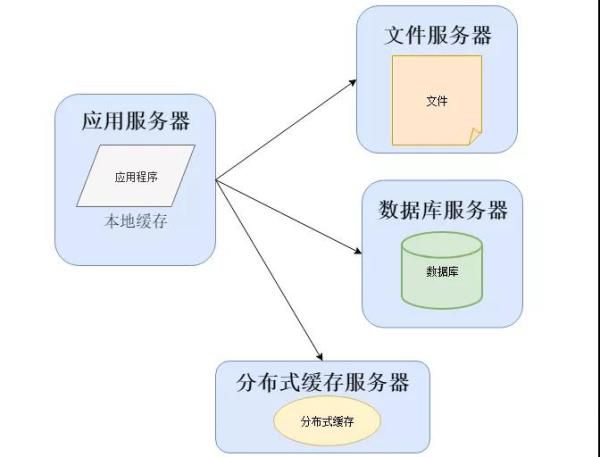
在大部分系統中,都會利用緩存技術改善系統的性能,使用緩存主要源于熱點數據的存在,大部分訪問都遵循28原則(即80%的訪問請求,最終落在20%的數據上)。
所以我們可以對熱點數據進行緩存,減少這些數據的訪問路徑,提高用戶體驗。
緩存實現常見的方式是本地緩存、分布式緩存。本地緩存,顧名思義是將數據緩存在應用服務器本地,可以存在內存中,也可以存在文件,OSCache就是常用的本地緩存組件。
本地緩存的特點是速度快,但因為本地空間有限所以緩存數據量也有限。
分布式緩存的特點是,可以緩存海量的數據,并且擴展非常容易,在軟件系統中常常被使用,速度按理沒有本地緩存快,常用的分布式緩存是Memcached、Redis。
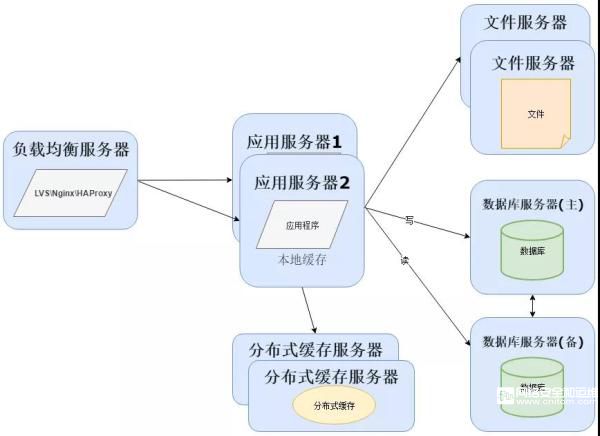
當然在用戶量繼續增長的情況下,應用服務器作為系統的入口,會承擔大量的請求,我們往往通過應用服務器集群來分擔請求數。
應用服務器前面部署負載均衡服務器調度用戶請求,根據分發策略將請求分發到多個應用服務器節點這時:

常用的負載均衡技術硬件的有F5,價格比較貴,軟件的有LVS、Nginx、HAProxy。
LVS是四層負載均衡,根據目標地址和端口選擇內部服務器,Nginx是七層負載均衡和HAProxy支持四層、七層負載均衡,可以根據報文內容選擇內部服務器。
因此LVS分發路徑優于Nginx和HAProxy,性能要高些,而Nginx和HAProxy則更具配置性,如可以用來做動靜分離(根據請求報文特征,選擇靜態資源服務器還是應用服務器)。
隨著用戶量繼續增加,數據庫成為最大的瓶頸,改善數據庫性能常用的手段是進行讀寫分離以及分表,讀寫分離顧名思義就是將數據庫分為讀庫和寫庫,通過主備功能實現數據同步。
分庫分表則分為水平切分和垂直切分,水平切換則是對一個數據庫特大的表進行拆分,例如用戶表。
垂直切分則是根據業務不同來切換,如用戶業務、商品業務相關的表放在不同的數據庫中:

業務量越來越大,產生的文件越來越多,單臺的文件服務器已經不能滿足需求。需要分布式的文件系統支撐。
常用的分布式文件系統有NFS:
由于項目數據量持續增加,數據庫的壓力會越來越大,并且傳統關系型數據無法處理海量數據。
這時需要分離數據存儲,對于海量數據的查詢和分析,我們使用NoSQL數據庫和大數據技術再加上搜索引擎可以達到更好的性能。
常用的NoSQL數據庫有MongoDB、HBase(依賴Hadoop大數據)、Redis,搜索引擎有Lucene、Solr、Elasticsearch等:

單獨軟件運維部門
當越來越多的開源或者非開源技術加入到項目中,項目成員也會變得越來越多,開始各司其職對現在使用的各種軟件進行運行維護和實施部署。
一個項目的具體實施并不是編寫一個應用程序那么簡單,還涉及到為應用程序提供支撐的其他軟件,這為單獨成立軟件運維部門提供了條件。
項目運行時間長了以后,會因為技術落后或者性能瓶頸而進行重構,軟件運維部門會和開發部門合作,對項目架構進行重構。
一般情況下開發會拆分業務,形成分布式應用程序,而應用拆分成分布式,可以使用阿里的Dubbo或者SpringCloud搭建服務:
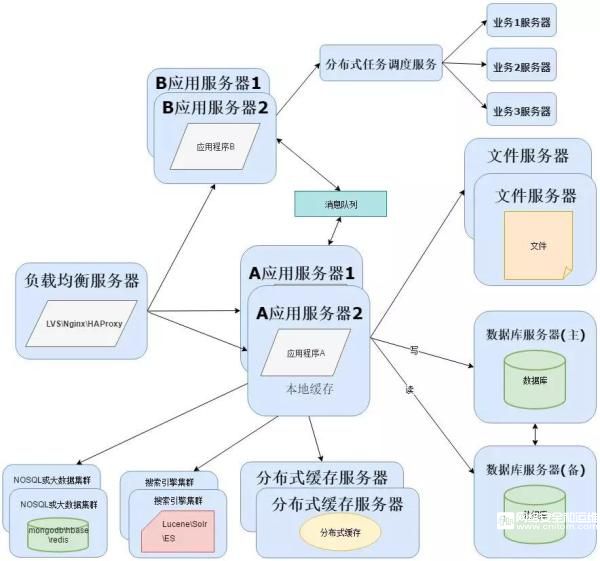
為了實現分布式系統,這里需要用到消息隊列,消息隊列的主要作用有3個:解耦、異步、削峰。
消息隊列可以選擇:RabbitMQ、ZeroMQ、ActiveMQ、Kafka。
軟件運維部門和開發部門融合
隨著技術的發展,近幾年自動化運維,自動化部署,自動化測試的興起,特別是DevOps概念的提出,運維部門和開發部門融合的趨勢越來越明顯。又開始了開發即是運維的輪回,但這次不同的是,機器替代了人肉運維。
DevOps就是開發(Development)和運維(Operations)這兩個領域的合并,那么,為什么要合并這兩個領域?
原因很多,但首要原因是:目前的兩個領域工作流程是脫節的,絕對的脫節。很多公司的開發部門和運維部門之間存在的深刻矛盾,其實就是這個“脫節”造成的。
為了解決“脫節”問題,需要使用到很多自動化工具,以及自動化維護平臺。于是架構進一步升級:
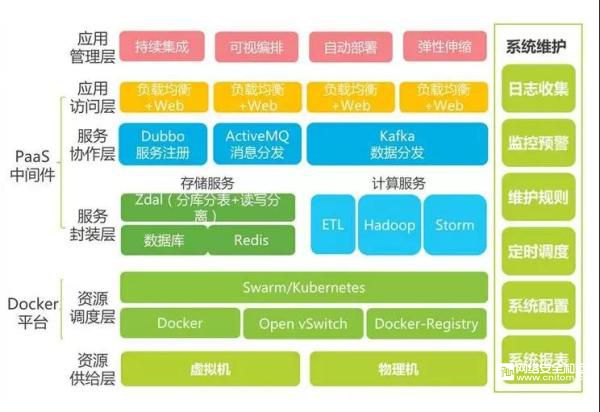
持續開發
與瀑布模型不同的是,軟件可交付成果被分解為短開發周期的多個任務節點,在很短的時間內開發并交付。
這個階段包括編碼和構建階段,并使用Git和SVN等工具來維護不同版本的代碼,以及Ant、Maven、Gradle等工具來構建/打包代碼到可執行文件中,這些文件可以轉發給自動化測試系統進行測試。
持續測試
在這個階段,開發的軟件將被持續地測試Bug。對于持續測試,使用自動化測試工具,如Selenium、TestNG、JUnit等。
這些工具允許質量管理系統完全并行地測試多個代碼庫,以確保功能中沒有缺陷。
在這個階段,使用Docker容器實時模擬“測試環境”也是首選。一旦代碼測試通過,它就會不斷地與現有代碼集成。
持續集成
這是支持新功能的代碼與現有代碼集成的階段。由于軟件在不斷地開發,更新后的代碼需要不斷地集成,并順利地與系統集成,以反映對最終用戶的需求更改。
更改后的代碼,還應該確保運行時環境中沒有錯誤,允許我們測試更改并檢查它如何與其他更改發生反應。
Jenkins是一個非常流行的用于持續集成的工具。使用Jenkins,可以從Git存儲庫提取最新的代碼修訂,并生成一個構建,最終可以部署到測試或生產服務器。
可以將其設置為在Git存儲庫中發生更改時自動觸發新構建,也可以在單擊按鈕時手動觸發。
持續部署
它是將代碼部署到生產環境的階段。在這里,我們確保在所有服務器上正確部署代碼。
如果添加了任何功能或引入了新功能,那么應該準備好迎接更多的網站流量。因此,系統運維人員還有責任擴展服務器以容納更多用戶。
由于新代碼是連續部署的,因此配置管理工具可以快速,頻繁地執行任務。Puppet,Chef,SaltStack和Ansible是這個階段使用的一些流行工具。
容器化工具在部署階段也發揮著重要作用。Docker和Kubernetes是流行的工具,有助于在開發,測試,登臺和生產環境中實現一致性。除此之外,它們還有助于輕松擴展和縮小實例。
持續監控
通過監控軟件的性能來提高軟件的質量。這種做法涉及運營團隊的參與,他們將監視用戶活動中的錯誤/系統的任何不正當行為。
這也可以通過使用專用監控工具來實現,該工具將持續監控應用程序性能并突出問題。
使用的一些流行工具是Splunk、ELKStack、Nagios、NewRelic和Sensu。
這些工具可幫助密切監視應用程序和服務器,以主動檢查系統的運行狀況。它們還可以提高生產率并提高系統的可靠性,從而降低IT支持成本。
發現的任何重大問題都可以向開發團隊報告,以便可以在持續開發階段進行修復。
小結
軟件架構不是一蹴而就的,系統架構并不是一開始設計時就具備完整的高性能、高可用、高伸縮等特性的,它是隨著用戶量的增加,業務功能的擴展逐漸演變完善的。
在這個過程中,開發模式、技術架構、設計思想也發生了很大的變化,就連技術人員也從幾個人發展到一個部門甚至一條產品線。
這就像物種的演變,從簡單到復雜,但是越是復雜的生物,要生存所付出的代價也會越多。反而簡單的生物存活的更久更好更成功,這就是遞弱代償。
系統架構越來越復雜,確實能應付很多情況,但付出的運維成本也會越來越大,于是又開始將分工出去的運維部分融合,也許過一段時間,又會出現新的分工,誰知道呢?
作者:李博文
簡介:新炬網絡高級工程師。精通Java開發和運維,開發過運營商系統,物聯網系統,電網系統,燃氣系統,高校系統等大型系統,擁有ITSS服務經理,項目管理師,架構師等認證,擁有豐富的開發經驗,擅長軟件開發與運維。


