

(MeSSrro/Shutterstock)
數據湖預測
從 Hadoop 繼續前進: 2023 年,DuckDB (C++)、Polars (Rust) 和 Apache Arrow (Go、Rust、Javascript 等)等工具變得非常流行,將 JVM 和 C/Python 在分析領域的完全主導地位出現裂縫。
我們預測,JVM之外的創新步伐將會加快,這將現有的基于Hadoop的架構送入傳統抽屜當中。
雖然大多數公司已經沒有直接使用Hadoop,但目前的大部分技術仍然建立在Hadoop的腳本之上:Apache Spark完全依賴Hadoop的I/O實現來訪問其底層數據。許多湖倉一體架構要么基于 Apache Hive 樣式,要么更直接地基于 Hive 元存儲及其接口,以在其存儲層之上創建表格抽象。
雖然Hadoop和Hive本身并沒有問題,但它們已經不再代表最先進的技術。這次,它們完全基于JVM。JVM現在的性能令人難以置信,當然如果想從沒有變得更快的CPU中獲得絕對最好的選擇,這仍然不太可能。
此外,Apache Hive通過抽象出Hadoop的底層分布式特性,并在分布式文件系統之上暴露熟悉的SQL(-ish)表抽象,這標志著大數據處理向前邁出了一大步。由此可以看到,它已經開始顯示年齡和局限性:缺乏事務性和并發性控制,缺乏元數據和數據之間的分離。 以及我們在 15+ 年中學到的其他經驗教訓。
今年,我們將看到 Apache Spark 從根源上繼續前進:Databricks 已經有一個無 JVM 的 Apache Spark (Photon) 實現,而新的表格式(如 Apache Iceberg)也通過實現表目錄的開放規范,以及為 I/O 層提供更現代的方法,并從集體 Hive 根源中走出來。
元商店之戰
隨著 Hive 即成為過去,以及 Delta Lake 和 Iceberg 等 Open Table 格式變得無處不在,任何數據架構中的核心組件也正在被取代——“元存儲”。對象存儲或文件系統上的文件與它們所表示的表格和實體之間的間接層。雖然表格格式是開放的,但它們的元存儲似乎越來越專有和鎖定。
Databricks 正在積極推動用戶使用其 Unity Catalog,AWS 擁有 Glue,Snowflake 也有自己的目錄實現。這些是不可互操作的,并且在許多方面成為希望利用新表格格式提供開放性的用戶鎖定供應商的一種手段。我們預測,在某個時候,鐘擺會擺回去——因為用戶將朝著更高的標準化和靈活性方向發展。
大數據工程作為一種實踐將走向成熟
隨著分析和數據工程變得越來越普遍,大量的技術正在快速增長,最佳實踐也開始出現。
2023 年,我們看到促進結構化開發-測試-發布數據工程方法的工具變得更加主流。DBT非常受歡迎和成熟。從Great Expectations、Monte Carlo和其他質量和可觀測性平臺等工具的成功來看,可觀測性和監控現在也被視為不僅僅是錦上添花。lakeFS 提倡對數據本身進行版本控制,以允許類似 git 的分支和合并,從而構建健壯的、可重復的開發-測試-發布管道。
此外,我們現在還看到,從Snowflake和Databricks到初創公司,每個人都在推廣數據網格和數據產品等模式,以填補圍繞這些模式仍然存在的工具空白。
因此,我們將在 2024 年看到旨在幫助用戶實現這些目標的工具激增。從以數據為中心的監控和日志記錄到測試工具和更好的 CI/CD 選項,軟件工程實踐還有很多工作要做,現在是縮小這些差距的正確時機。
服務層預測
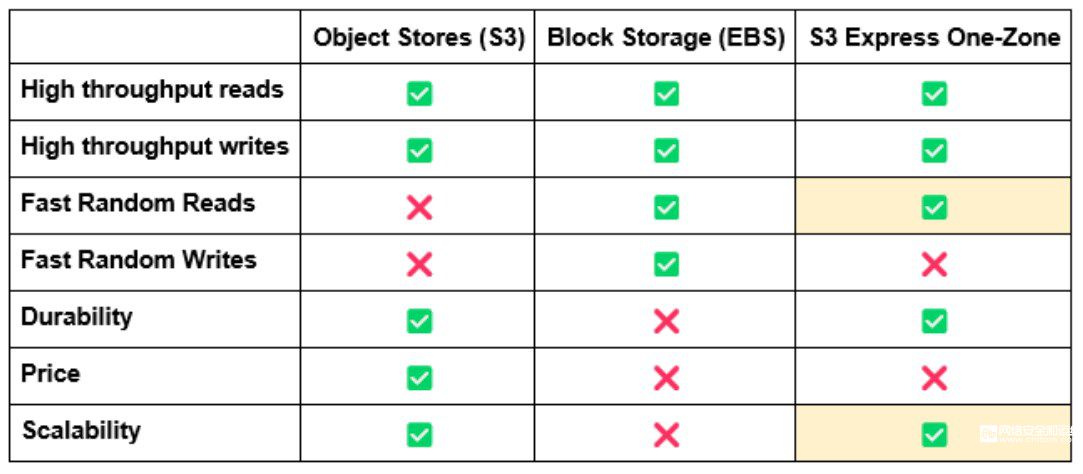
云原生應用程序將把更大份額的狀態轉移到對象存儲中: 2023 年底,AWS 宣布了自 2006 年成立以來最大的功能之一,即其核心存儲服務 S3。
該功能“S3 Express One-Zone”允許用戶使用與 S3 提供的相同*標準對象存儲 API,但訪問數據的延遲始終如一的堅持個位數毫秒,成本大約是 API 調用的一半。
這標志著一個巨大的變化。到目前為止,對象存儲的用例有些狹窄:雖然它們允許存儲幾乎無限量的數據,但即使您只想讀取少量數據,您也必須接受更長的訪問時間。
這種權衡顯然使它們在分析和大數據處理中非常受歡迎。因為在這些領域,延遲通常不如整體吞吐量重要,但這意味著數據庫、HPC 和面向用戶的應用程序等低延遲系統不能真正依賴它們作為其關鍵路徑的一部分。
如果他們使用了對象存儲,則通常采用存檔或備份存儲層的形式。如果想要快速訪問,則必須選擇以某種形式附加到實例的塊存儲設備,并放棄對象存儲提供的可擴展性和持久性優勢。我們相信 S3 Express One-Zone 是改變這種狀況的第一步。
S3 是新的磁盤驅動器,通過一致、低延遲的讀取,現在理論上可以構建完全不依賴塊存儲的完全對象存儲支持的數據庫。
我們預測,在2024年,我們將看到更多的可操作數據庫開始在實踐中采用這一概念:允許數據庫在完全短暫的計算環境中運行,完全依靠對象存儲來實現持久性。
(圖片來源:Oz Katz)
業務數據庫將開始分解
考慮到前面的預測,我們可以將這種方法更進一步:如果我們像標準化 OLAP 一樣標準化 OLTP 的存儲層會怎樣?
數據湖的最大承諾之一是能夠將存儲和計算分開,以便一種技術寫入的數據可以被另一種技術讀取。這使開發人員可以自由選擇最適合其用例的最佳堆棧。但是,有了 Apache Parquet、Delta Lake 和 Apache Iceberg 等技術,現在這是可行的。
如果我們設法將用于操作數據訪問的格式標準化,會怎么樣?讓我們想象一個鍵/值抽象(可能類似于 LSM sstables?),它允許存儲排序的鍵值對,為對象存儲進行最佳布局。
我們可以部署一個無狀態的RDBMS,在上面提供查詢解析/規劃/執行功能,甚至作為一個按需的lambda函數。另一個系統可能會使用相同的存儲抽象來存儲用于搜索的反排索引,或者用于存儲酷炫的生成式 AI 應用程序的向量相似性索引。
雖然不相信一年后我們會將所有數據庫作為 lambda 函數運行,但確實將看到從“對象存儲作為存檔層”到更多“對象存儲作為記錄系統”的轉變,在操作數據庫中也會發生。

(圖片來源:Oz Katz)
最后的思考
樂觀地認為,2024 年將繼續朝著正確的方向發展數據格局:更好的抽象、改進堆棧不同部分之間的接口,以及技術發展的新功能。
雖然它們并不總是完美的,以犧牲易用性會以較低的靈活性為代價。但是,在過去二十年中,看到這個生態系統的發展,我認為我們的狀況比以往任何時候都好。
我們比以往任何時候都有更多的選擇、更好的協議和工具,以及更低的進入門檻。
文章標題:Data Engineering in 2024: Predictions For Data Lakes and The Serving Layer
文章作者:Oz Katz


