
從視頻會議到遠程醫療,從連麥開黑到陪伴社交,疫情常態化加速了線下活動線上化,逐漸改變了人們的生產生活方式。其中,音頻質量很大程度上影響著通話體驗,而噪聲又很大程度決定音頻質量。比如,居家辦公場景,就流傳著“居家辦公,必有鄰居裝修”的定律。也是因為裝修聲會很大程度影響參與效率,所以對居家辦公的同學帶來了很大的影響。火山引擎 RTC,集成了自研的深度學習降噪方案,來應對游戲、互娛、會議等實時音視頻溝通場景下的噪聲影響。
讓我們看一下 RTC AI 降噪在會議、游戲、居家場景下的降噪效果對比。
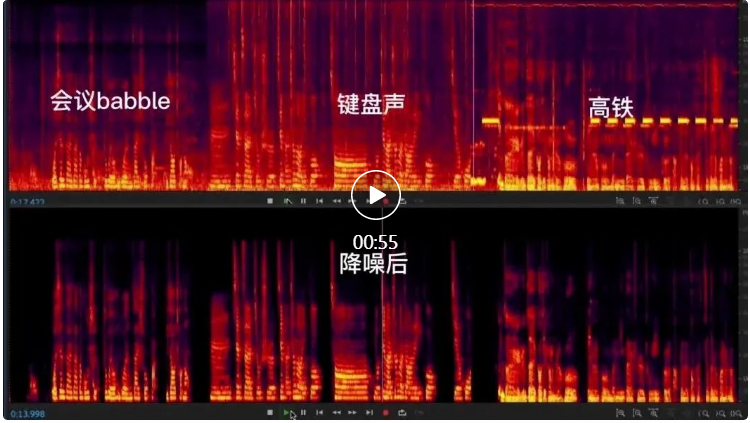
會議場景

游戲場景
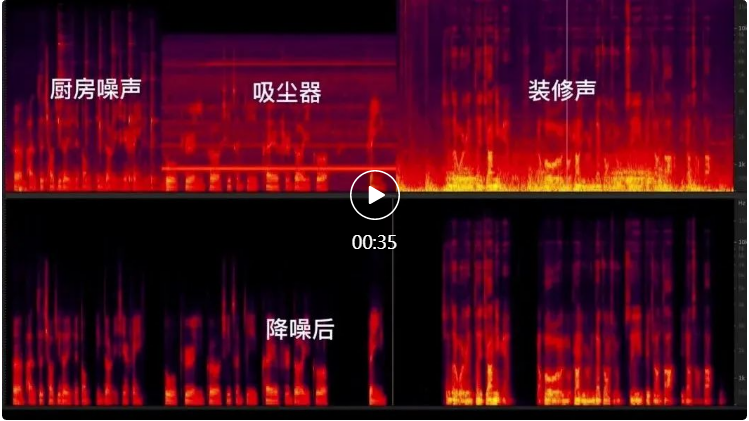
居家場景
通過上面的對比效果可以明顯看到不同噪聲對線上生產、生活場景的影響,以及通過 AI 降噪達到的降噪效果。RTC AI 音頻降噪采用了經典的CRN網絡結構【參考文獻 1】作為降噪框架。CRN 網絡結構由 Encoder、Recurrent Layer 和 Decoder 三部分組成。這種結構兼具了 CNN 的深層特征抽取能力和遞歸網絡的記憶能力,表現出了比純 CNN 網絡或者純 GRU 網絡更好的降噪能力。

CRN網絡結構
在具體落地到產品的過程中,我們在上述基礎模型中,解決了實際場景中出現的五大問題:
- 如何應對各種復雜的設備,多樣的環境
- 如何在滿足低延時條件下,提升模型效果
- 如何在滿足低計算量條件下,提升模型效果
- 如何平衡強降噪和高保真
- 如何應對對音樂的損傷
通過解決上述問題,可以有效提升算法的速度、實時性和穩定性,保證在語音無損傷的情況下最大程度地實現噪聲抑制,提升實時音視頻場景,特別是會議、音樂等復雜場景下的互動體驗。下面具體展開講下我們是分別如何解決上述五大問題的。
一、訓練數據增廣
在我們實際生活中,降噪算法所需要面臨的場景是非常復雜多樣的。
拿“會議”場景舉例,開會環境的多樣性給降噪算法帶來了不少挑戰:在座位上開會,設備會采集到鄰座工位上的說話聲,此時我們期望算法能去除一定的背景說話人聲;在會議室中開會,由于說話人離麥克風的距離各不相同,此時降噪算法面臨著多人聲、遠距離拾音、混響的難題;如果是在公交、地鐵、高鐵上開會,除了人聲,還會引入車輛信號、報站等聲音。還有比如在室內玩游戲使用游戲語音的例子,此時,場景中的噪聲除了環境噪聲,還有敲擊屏幕或鍵盤、拍桌子等各類噪聲,此時就需要降噪算法能夠盡量抑制足夠多類別的噪聲。

不僅如此,在不同環境下常用的設備也是不盡相同的。常用設備主要可以歸類為以下幾類:

除了使用場所有所差別,另外一個主要差異點在于不同設備的采集特性不同,并且自帶了不同的音頻前處理算法,以現在主流的安卓手機為例,往往出廠就自帶了強抑制降噪算法,但在實際體驗中仍然存在噪聲較多以及人聲損傷問題,那么就需要我們的降噪算法去適配這一類“二手”音頻數據,包括需要去覆蓋殘留形態的噪聲數據,以及損傷形態的人聲數據。
除此之外,個人外接設備也需要特別小心,比如有線耳機可能會帶來高頻噪聲,而藍牙耳機可能引入連接不穩定的問題,并且降噪耳機還攜帶有額外的音頻處理能力。
我們將在數據增廣過程中著重應對這類問題。將增廣中噪聲的類型打上標簽、對不同的場景使用不同的增廣配置文件即可配置不同的訓練增廣方案。下面簡單說明一下我們常用的訓練數據增廣手段。
基本增廣手段包括:
- 音量調整:現實生活中采集到的音量大小往往不同,用于模擬不同采集音量的情況;
- 高低通濾波:不同設備的有效頻率不同,如藍牙耳機往往只有 4k 的有效頻段;
- 削波模擬:模擬爆音之后的音頻效果;
- 房間沖擊響應:模擬不同房間下的混響場景;
- 破音信號模擬:增加對丟幀信號的模擬
- 模擬噪聲變化:模擬不同噪聲環境,如常見場景的噪聲疊加和變化;?
我們近期針對語音中的嘯叫信號著重進行了模擬和處理。通過線下采集,以及線上仿真模擬的方式生成了大量的不同嘯叫周期、頻率范圍的嘯叫語音,并以較低的信噪比融合進原始語音中。

嘯叫語音線上模擬
在增加了上述嘯叫數據的基礎上,我們又單獨對嘯叫語音施加強抑制的損失函數,消除了大部分的嘯叫語音。
我們測試了各種設備、各種場景下的 500+ 種噪聲,均能實現理想的消除效果。
二、壓縮模型計算量
實時率 (Real Time Factor) 是衡量算法的 CPU 消耗的指標。實時通信下場景,對模型算力要求極為苛刻。為了讓模型在移動端可流暢運行,我們主要在特征壓縮、模型精簡和引擎加速三個方面進行了改進。
(1) 特征壓縮
在原始的 CRN 的文章中,使用的是短時傅里葉 (STFT) 特征,如 WebRTC 中默認使用的 257 維的 STFT 特征。但是 STFT 在高頻處包含的信息量已經較少,根據人耳聽覺特性進行頻譜壓縮已經是常見的方案,如 RNNoise 中使用 ERB 方案。我們采用根據梅爾聽覺特性設計的濾波器進行頻譜壓縮的方案。

通過將高維特征壓縮到低維,能將計算量壓縮為原來的 1/3。
(2) 模型精簡
?如前文所述,我們使用了 CRN 結構作為主要的結構。為了將整體的模型的計算量進行進一步的壓縮,我們嘗試了很多的策略,主要包括:
- 將其中的卷積或者轉置卷積模塊替換為深度可分離卷積或者可分離轉置卷積
- 使用空洞卷積,使用更少層數能夠獲得更長的感受野
- 將 GRU 模塊替換為分組 GRU 模塊
- 使用稀疏化工具,進一步壓縮通道數的大小
通過上述一系列優化,模型的計算量被壓縮到數十兆 MACS 的計算量級,模型的參數量在 100K 以內。
(3) 引擎加速
最后我們在字節跳動的推理引擎 ByteNN 上,與智創語音團隊和 AI 平臺團隊合作,新增了適配音頻算法的流式推理能力,來提升設備上的計算效率。主要包括:
- 架構支持子圖推理 / 提前退出等流式推理能力節省算力
- 包括卷積 / GRU 等流式算子的支持
- ARM / X86 等平臺匯編級別優化加速
通過上述手段,目前將端到端的 48K 降噪模型的 RTF 指標在各端機型上都控制在 1% 以內。
三、降低延時
為了保證端到端延時在較低水平,AINR 直接使用 AEC 輸出的頻域特征作為輸入,減少了一次 ISTFT 和一次 STFT 的計算時間以及引入的(窗長-步長)的延時(一般在 20ms 左右)。然而在實驗中我們發現,由于 AEC 的非線性處理的操作是直接在頻譜的操作,導致了 STFT 的不一致性,即原始的 STFT 經過 ISTFT 后再做 STFT 的值與原始值不一致。所以直接使用 AEC 的頻域輸出(頻域特征 1 )作為模型的輸入和使用頻域特征 2 作為模型輸入的處理結果略有不同,前者在個別場景會出現語音損傷。

我們通過一系列的工程手段,解決了這種不一致性,使得處理過程可以繞過上述的 ISTFT 和 STFT 過程,節省了 20 毫秒以上的時間。如此節省下來的時間,可用于增加模型的延時,但保證系統的總體延時不會增加。增加模型的延時對區分清輔音和噪音有很大的幫助。如左、中例子所示,清輔音在頻譜和聽感上和噪聲十分接近,在不知道下文的情況下模型很難做出準確的判斷。于是我們引入 20~40ms 不等的較短延時,利用未來的信息幫助模型做當前幀的判斷,如右例子所示,加入延時后的非語音段要明顯比優化前干凈。
四、降噪與保真的平衡
降噪效果中,強降噪和高保真往往是天平的兩端,尤其是針對小模型。強力的降噪往往會帶來部分語音的損傷,對語音高保真往往會殘留部分的小噪聲。比如,在針對 babble 的降噪實驗過程中發現,如果采用強力降噪模型,能夠把辦公室的 babble 類噪聲都消除的很干凈,但是針對會議室的遠場語音就會帶來損傷。為了平衡這兩者,我們主要采取了如下的一些策略來改進:
- 剔除噪聲臟樣本:去掉包含“說話聲”的噪聲樣本,避免噪聲中包含內容清晰的語音,導致推理時將遠場人聲誤判為噪聲。
- 輸入特征進行幅度規整:保證不同幅度的語音提取的特征值是非常接近的,剔除幅度的影響。
- 在靜音段部分使用抑制力度大的損失函數,而在人聲部分使用保護力度更大的損失函數。來保證非語音段強降噪、而語音段高保真的目的。
- 針對小語音段,在計算損失函數時提升對于語音有損的懲罰力度。
我們以輕微帶噪語音的 PESQ 指標作為語音保真的指標。以純噪部分的殘留噪聲平均分貝作為噪聲抑制的指標。下表列出了幾次迭代在會議場景下的指標改進。
|
|
第一版 |
第二版 |
第三版 |
|
語音保留 |
3.72 |
3.76 |
3.85 |
|
噪聲殘留(dB) |
-75.88 |
-105.99 |
-111.03 |
從幾個版本降噪模型的客觀指標來看,語音保護指標在較小的范圍內波動,噪聲殘留則不斷減少。可以看出 RTC AI 降噪模型在較大程度保護語音的前提下,噪聲抑制力度不斷提升。
五、實時音樂識別
在互娛場景,往往有較多的音樂場景。由于部分音樂元素和噪聲的特點非常接近,如果直接應用深度學習降噪模型,音樂會被壓制得很卡頓。如果把音樂保護加入模型訓練,其他語料中的噪聲壓制的效果會受到影響。因此,準確識別出聲音是音樂還是噪聲就變得非常重要,能在識別出音樂之后關閉降噪,同時也不會影響正常場景下的降噪力度。
我們的音樂識別模型和【參考文獻 2】方法非常相似。都是在 PANNS 【參考文獻 3】的 527 類語音檢測的基礎上,使用語音、音樂和噪聲三類數據進行微調。考慮這類方法的一個主要原因是利用 CNN 對長時語音(4 秒窗長)進行建模,以 0.33 秒為步長輸出判別結果,來代替如 GRU 類模型幀級別的輸出,從而增強識別的效果和穩定性。相對于原文,我們進一步對模型進行了壓縮和裁剪,達到了 4M FLOPS 的計算量 和 20KB 的參數量的尺寸,保證在低端的移動設備上可以運行。同時,在進入音樂時,增加 2 秒延時的多幀融合判斷以及離開音樂時 4 秒延時的多幀融合判斷,進一步提升了音樂識別的穩定性。在音樂誤識別率為 0% 的情況下,召回率達到了 99.6%。
下圖展示了 SIP 場景下的音樂共享場景的一個例子。因為 SIP 場景下,共享音樂和采集信號是混合后再傳輸的,所以共享的信號和采集的信號使用的是同樣的處理通路。在實際測試中,我們發現即使用很輕量級的傳統降噪方案也會對音樂產生損傷。通過使用音樂檢測,保護相對應的音樂段,可以有效緩解該損傷問題。

六、效果和指標的對比
通過上述幾點的改進,目前無論是主觀聽感,還是客觀指標,火山引擎 RTC 中的降噪算法已經處于行業領先位置。
我們在高中低三種信噪比條件的白噪聲、鍵盤聲、babble 噪聲、空調噪聲四種噪聲環境下以及 Windows 和 MAC 設備中,測試了火山引擎 RTC 和行業同類產品的降噪結果的 POLQA 分數。從表中可以看出,無論是在這四種噪聲場景上,還是在不同設備上,我們的降噪算法均優于同類產品。?

展望
在應用 AI 降噪之后,我們能夠消除環境噪聲帶來的各種影響。但除了噪聲影響之外,影響語音質量的還包括采集硬件的損傷、硬件處理算法的損傷、傳輸通道的損傷等等,后續我們會進一步在軟件算法中緩解這些損傷,以期達到使用任何硬件均能達到類似錄音棚的高音質效果。
參考文獻
【1】Tan K, Wang D L. A convolutional recurrent neural network for real-time speech enhancement[C]//Interspeech. 2018, 2018: 3229-3233.
【2】Reddy C K A, Gopa V, Dubey H, et al. MusicNet: Compact Convolutional Neural Network for Real-time Background Music Detection[J]. arXiv preprint arXiv:2110.04331, 2021.
【3】Kong Q, Cao Y, Iqbal T, et al. Panns: Large-scale pretrained audio neural networks for audio pattern recognition[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28: 2880-2894.?


