
為了提供實時分析,公司需要一個現代技術基礎設施,包括這三點。
一個實時數據源,如網絡點擊流、傳感器產生的物聯網事件等。
一個平臺,如ApacheKafka/Confluent,Spark或AmazonKinesis用于發布該事件數據流。
一個實時分析數據庫,能夠連續攝取大量的實時事件,并在幾毫秒內返回查詢結果。
事件流/流處理已經存在了近十年。它已被充分理解。而實時分析則不然。實時分析數據庫的技術要求之一是可變性。可變性是一種超級能力,它能夠對數據存儲中的現有記錄進行更新或變異。
可變和不可變數據之間的區別
在我們談論為什么可變性是實時分析的關鍵之前,重要的是了解什么是可變性。
可變數據是指存儲在表記錄中的數據,可以被擦除或用更新的數據來更新。例如,在一個雇員地址的數據庫中,假設每條記錄都有個人的姓名和他們當前的居住地址。如果雇員從一個地方搬到另一個地方,當前的地址信息將被覆蓋。
傳統上,這些信息會被存儲在交易型數據庫中----。OracleDatabase,MySQL,PostgreSQL等--因為它們允許可變性。存儲在這些交易型數據庫中的任何字段都是可更新的。對于今天的實時分析,我們還有很多其他的原因需要可變性,包括數據的豐富性和回填數據。
不可變的數據則相反--它不能被刪除或修改。更新不是寫在現有的記錄上,而是只做追加。這意味著更新被插入到不同的位置,或者你被迫重寫新舊數據以正確存儲它。稍后會有更多關于這個缺點的內容。不可變的數據存儲在某些分析場景中是很有用的。
不變性的歷史作用
數據倉庫普及了不變性,因為它減輕了可擴展性,特別是在分布式系統中。分析性查詢可以通過在RAM或SSD中緩存大量訪問的只讀數據來加速進行。如果緩存的數據是易變的,并且有可能發生變化,那么就必須不斷地與原始數據進行核對,以避免變得陳舊或錯誤。這將增加數據倉庫的操作復雜性;另一方面,不可變的數據則不會產生這樣的問題。
不變性也減少了意外刪除數據的風險,這在某些用例中是一個重要的好處。以醫療保健和病人健康記錄為例。像新的醫療處方會被添加,而不是寫在現有的或過期的處方上,這樣你總是有一個完整的醫療記錄。
最近,一些公司試圖將Kafka和Kinesis等流發布系統與用于分析的不可變的數據倉庫配對。這些事件系統捕獲物聯網和網絡事件,并將其存儲為日志文件。這些流式日志系統很難查詢,所以人們通常會將日志中的所有數據發送到一個不可變的數據系統,如ApacheDruid來執行批量分析。
數據倉庫將把新流的事件附加到現有的表格中。由于過去的事件在理論上是不會改變的,因此不可更改地存儲數據似乎是一個正確的技術決定。雖然一個不可變的數據倉庫只能按順序寫入數據,但它確實支持隨機數據讀取。這使得分析性商業應用能夠有效地查詢數據,無論何時何地,它都被存儲起來。
不變數據的問題
當然,用戶很快發現,由于許多原因,數據確實需要更新。這對于事件流來說尤其如此,因為多個事件可以反映現實生活中物體的真實狀態。或者網絡問題或軟件崩潰會導致數據延遲交付。晚到的事件需要被重新加載或回填。
公司也開始接受數據豐富化,將相關數據添加到現有表格中。最后,公司開始不得不刪除客戶數據,以履行消費者隱私法規,如GDPR和其"被遺忘的權利"。"
不可變的數據庫制造商被迫創造變通方法,以便插入更新。一個流行的方法是由ApacheDruid和其他公司使用的一種流行方法被稱為寫時復制。數據倉庫通常將數據加載到一個暫存區域,然后再分批攝入數據倉庫,在那里進行存儲、索引并為查詢做好準備。如果有任何事件延遲到達,數據倉庫將不得不寫入新的數據,并將其保存在數據倉庫中。重寫臨近數據以便以正確的順序正確地存儲所有數據。
在一個不可改變的數據系統中處理更新的另一個糟糕的解決方案是將原始數據保留在分區A(上面),并將晚到的數據寫入不同的位置,即分區B。應用程序,而不是數據系統,將不得不跟蹤所有鏈接但分散的記錄的存儲位置,以及任何由此產生的依賴關系。這個過程被稱為參考完整性,必須由應用軟件來實現。

這兩種解決方法都有很大的問題。寫時復制要求數據倉庫花費大量的處理能力和時間--當更新很少的時候還可以忍受,但隨著更新數量的增加,成本和速度都是無法忍受的。這就造成了嚴重的數據延遲,可能排除了實時分析。數據工程師還必須手動監督寫入時的復制,以確保所有新舊數據被準確寫入和索引。
實施參照完整性的應用程序有其自身的問題。查詢必須反復檢查他們是否從正確的位置提取數據,否則就有可能出現數據錯誤。當同一記錄的更新分散在數據系統的多個地方時,嘗試任何查詢優化,如緩存數據,也變得更加復雜。雖然這些在節奏較慢的批處理分析系統中可能是可以容忍的,但當涉及到關鍵任務的實時分析時,它們是巨大的問題。
可變性有助于機器學習
在Facebook,我們建立了一個ML模型,在所有新的日歷事件被創建時掃描它們,并將其存儲在事件數據庫中。然后,實時地,一個ML算法將檢查這個事件,并決定它是否是垃圾郵件。如果它被歸類為垃圾郵件,那么ML模型代碼將在現有的事件記錄中插入一個新字段,將其標記為垃圾郵件。因為有這么多的事件被標記并立即被刪除,為了提高效率和速度,數據必須是可變的。許多現代的ML服務系統都效仿我們的例子,選擇了可變的數據庫。
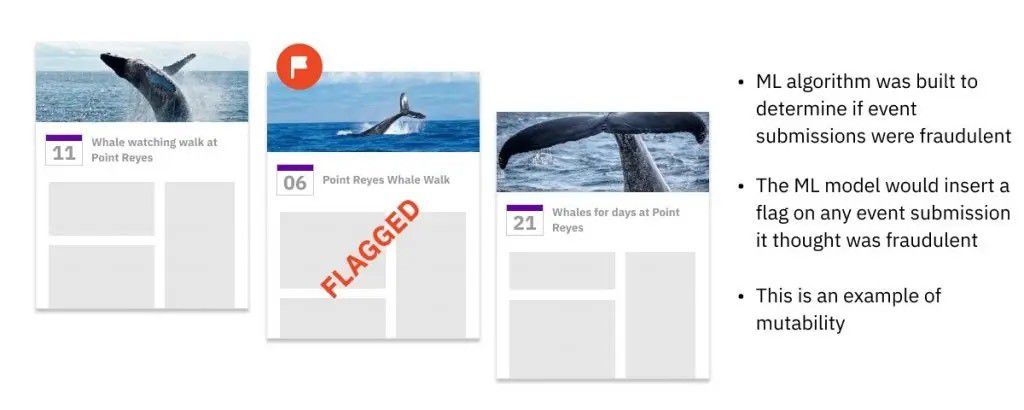
這種水平的性能在不可改變的數據中是不可能的。一個使用寫時復制的數據庫將很快被它必須更新的標記事件的數量所拖累。如果數據庫將原始事件存儲在分區A,并將標記的事件附加到分區B,這將需要額外的查詢邏輯和處理能力,因為每個查詢都必須合并兩個分區的相關記錄。這兩種解決方法都會給我們的Facebook用戶帶來難以忍受的延遲,增加數據錯誤的風險,并給開發人員和/或數據工程師帶來更多的工作。

可變性如何實現實時分析
在Facebook,我幫助設計了可變的分析系統,提供實時的速度、效率和可靠性。
我創立的技術之一是開源的RocksDB的高性能鍵值引擎,該引擎被MySQL、ApacheKafka和CockroachDB.RocksDB的數據格式是一種可變的數據格式,這意味著你可以更新、覆蓋或刪除一條記錄中的個別字段。它也是Rockset的嵌入式存儲引擎,Rockset是我創立的一個實時分析數據庫,具有完全可變的索引。
通過調整開源的RocksDB,可以實現對事件和更新的SQL查詢,而這些事件和更新僅在幾秒鐘前到達。這些查詢可以在低至幾百毫秒的時間內返回,即使在復雜的、臨時的和高并發的情況下。RocksDB的壓縮算法還能自動合并舊的和更新的數據記錄,以確保查詢訪問最新的、正確的版本,并防止數據膨脹,以免妨礙存儲效率和查詢速度。
通過選擇RocksDB,你可以避免不可改變的數據倉庫的笨拙、昂貴和產生錯誤的變通方法,如寫時復制和在不同分區中分散更新。
總而言之,可變性是當今實時分析的關鍵,因為事件流可能是不完整的或失序的。當這種情況發生時,數據庫將需要糾正和回填丟失和錯誤的數據。為了確保高性能、低成本、無錯誤的查詢和開發人員的效率,你的數據庫必須支持可變性。?


